
Recently, we have been going through upgrading our 65 apps to the newest release (v17). You might wonder: upgrade? Wasn’t this supposed to be seemless?
Well, let me explain what we did, how we handle stuff internally – and then maybe it does make sense to you why we take the steps we took for upgrades like this. 😉
DevOps
It seems I can’t stop talking about DevOps ;-). Well, it’s the one thing that “keeps us safe” regarding:
- Code quality
- Succeeding tests
- Breaking changes
- Conflicting number ranges
- … (and SO MUCH MORE)
You have to understand, in a big development team, you can’t just set it on hold, you can’t just let everyone contribute to the same issue (in this case: preparing your code for v17), you will probably continue development while somebody is prepping the code for the next version.
That’s where branching comes in (we just created a “v17prep” branch for every repo). Sure, we continued development, but once in a while, we basically just merged the master-version into the v17prep branch.
Now, with our DevOps pipelines, we want to preserve code quality, and some of the tools we use for that, are the code analyzers that are provided by Microsoft. Basically: we don’t accept codecop-warnings. So, we try to keep the code as clean as possible, partly by complying with the CodeCops (most of them) that Microsoft comes up with. The pipelines basically fails from the moment there is a warning.. .
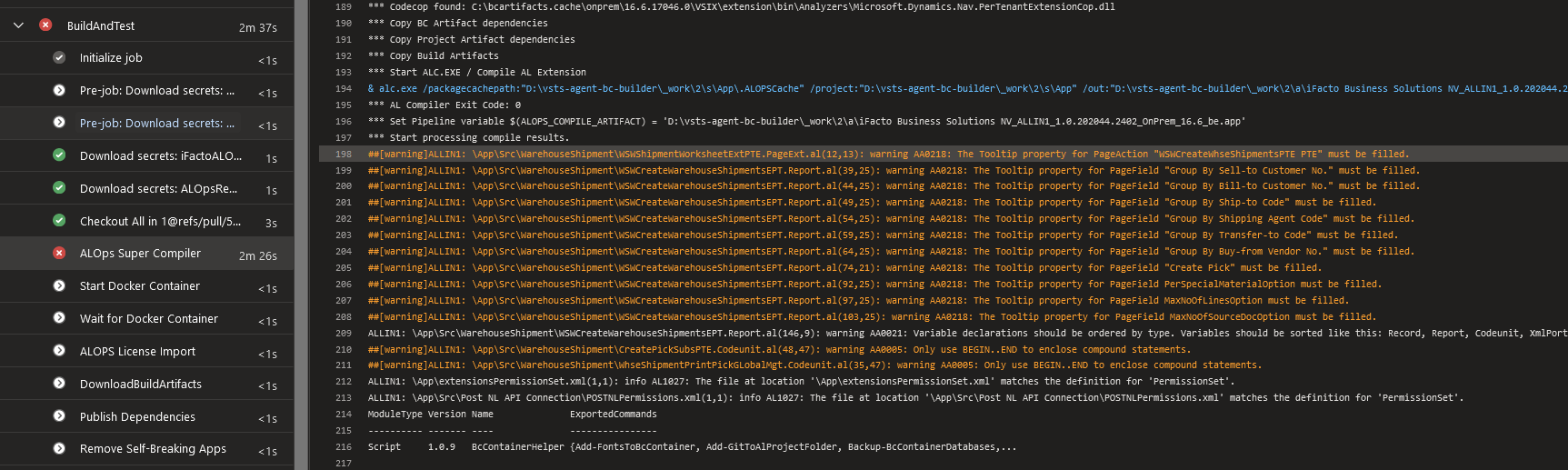
I absolutely love this. It is a way to keep the code cleaner than we were able to with C/SIDE. And the developer is perfectly able to act on these failures, quickly and easily, because they get feedback from the pipelines.
But – it comes with challenges as well:
- CodeCops are added by Microsoft with new compilers in VSCode. They are automatically being installed in VSCode. So it could very well happen that on a given morning, lots of new failures pop up your development environment.
- CodeCops are added in new versions of BC – so pipelines begin to fail from the moment pipelines are run against a higher version. Since we are upgrading … you feel what will happen, right? ;-).
Next, obviously, we have “automated testing” also deeply rooted in our DevOps: not a single PullRequest is able to be merged with the stable branch, if not all tests have run successfully. When implementing upgrades, I can promise you, there will be breaking tests (tests will simply fail for numerous reasons – Microsoft changed behaviour, your tests fails) – and if not, well, may be you didn’t have enough tests yet ;-): the more tests you have, the more likely one will fail because of an upgrade.
And that’s totally ok! Really. This is one of the reasons why we have tests, right? To know whether an upgrade was successful? So, absolutely something the pipeline will help us with during an upgrade process!
Yet another check, and definitely not less important: the “breaking change” check. The check that prevents us to allow any code that is breaking against a previous version of our app. It’s easy:
- We download the previous version of the app from the previous successful (and releasable) CI Pipeline.
- We install it in our pipeline on a docker container
- Then we compile and install the new version of our app
- If this works: all is well, if not, probably it’s because of a breaking change which we need to fix (Tip: using the “force”, is NOT a fix .. It’s causing deployment problems that you want to manually manage, trust me: don’t build in a default “force deploy” in a Release Pipeline ending up with unmanaged data loss sooner or later).
That’s the breaking change – but do know that in that same pipeline, we also run tests. And in order to do that, we need a container that has my app and my test app in it. Andin order to do THAT, we need all dependent apps in there as well. So, we always:
- Download all dependent apps from other pipelines – again the previously successful CI Pipeline of the corresponding app.
- Then install all of them so our new app can be installed having all dependencies in place
- If this doesn’t work: that’s probably a breaking dependency, which we’ll have to fix in the dependent app.
A breaking dependency is rather cumbersome to fix:
- First create a new pullrequest that fixes the dependent app
- Wait for it to run through a CI pipeline so you have a new build that you can use in all apps that has this one as a dependency
- The app with the dependency can pick it up in its pipeline
So in other words: it’s a matter of running the pipelines in a specific order, before all apps are again back on track. It’s a lot of manually starting pipelines, waiting, fixing, redo, …
I’m not saying there are different ways to do this, like putting everything in one repository, one pipeline, .. (which also has its caveats), but having all apps in its own repository really works well for us:
- It lets us handle all apps as individual apps
- It prevents to make unintentional/unmanaged interdependencies between apps
- It lets us easily implement unit tests (test apps without being influenced by other apps being installed)
- It notifies us from any breaking changes, breaking dependencies, forbidden (unmanaged) dependencies, …
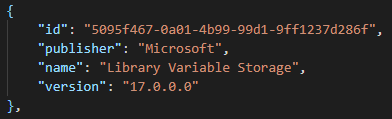
Why am I telling you this? Well, because Microsoft broke a dependency – a classic breaking change, but not in the base app, but in testability .. acceptable by Microsoft because “it’s just a test-framework”, but quite frustrating and labor intensive when this needs to go through a series of DevOps pipelines. The broken dependency was a simple codeunit (Library Variables Storage) that Microsoft moved to a new app.

I get why they did it: this is more of a “system library” than a “function library”, and basically the system app needs to be able to get to this, which shouldn’t rely on anything “functional”. So architecturally, I totally understand the change. But .. It’s breaking “pur sang”, and I really hope things like this will be done using obsoletions in stead of just “moving” .. . I’ll explain later what it involved to handle this issue for v17.
Since we want to comply with all codecops, implement all new features with V17, I think I found a method that works for us to be able to work on it, spread over time.
The flow
So, DevOps (and SCM) is going to be the tool(s) that we will use to efficiently and safely tackle these problems.
Step 1 Create branch
I already mentioned this – all preparation can be done in a new branch. Just create a new branch from your stable branch (master?), in which you can do all your preparation jobs. When people are still adding features in the meantime, simply merge the branch again with the new commits from time to time – possibly adding new code that does not comply with the new version anymore – but that should easily be fixed.. .
Step 2 Disable the (new) codecops that cause problems (warning or error)
This step is in fact the time that you buy yourself. You make sure that you still comply with all rules you did not disable, but to start working on all rules that you don’t comply with yet, let’s first disable them, to later enable them one-by-one to have a clear focus when solving them. For us, this meant we added quite a bunch of codecops:
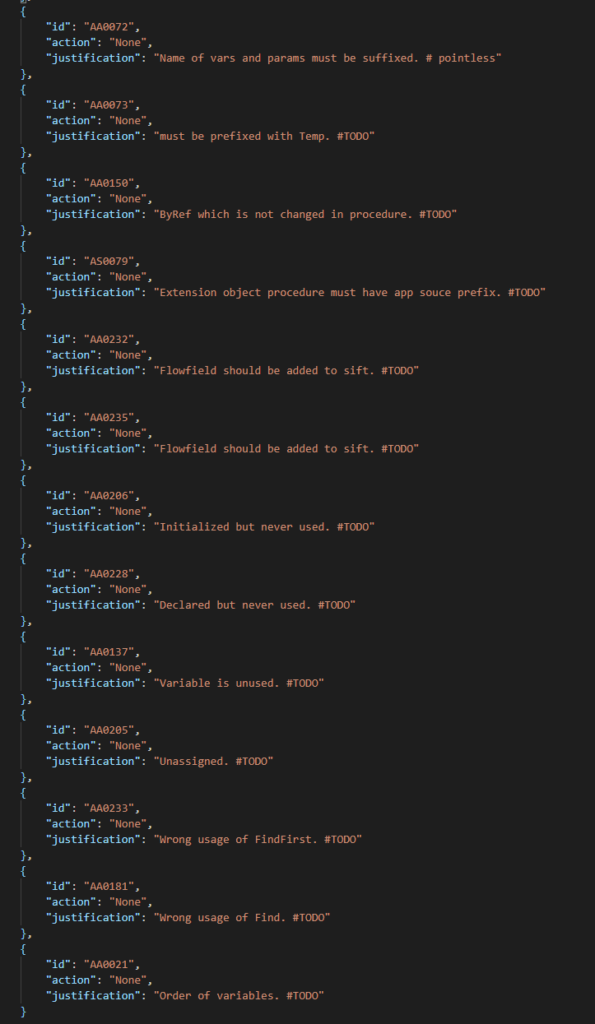
All of which we meant to fix. Some more efficiently than others .. . I wanted to comply with most of them.
Step 3 Make sure it compiles and publishes
It wasn’t “just” codecops that we needed to worry about. As said, there was also a breaking change: the “Library – Variable Storage” codeunit that moved to its own app. Now, lots of our test-apps make use of that codeunit, so we needed to add a dependency in all our test-apps to be able to “just” run our tests against the v17 dev environments:
Step 4 Enable codecop and fix
Up until this point, it only took us about 30 minutes: creating a v17 container, branch, disable codecops .. all find/replace so we efficiently did the same for all apps .. and we were good to go: we had apps (and its test-app) that did NOT show any warning in the problems-window, and that was able to be published to a default V17 container where we were able to run tests. Time to get busy!
To solve the codecops, we simply applied this subflow:
- Switch on a rule by removing it from the ruleset-file
- Commit
- Solve all warnings
- Commit
- Back to 1
And we did that until all rulesets we wanted to fix, were fixed.
Step 5 Pullrequest
From that moment, we started to pullrequest our apps to the master-branch, to perform our upgrade. Basically, I wanted to have all working pullrequest validation builds, before I started to approve them all to master branches. This was a very tricky thing to do ..well .. this was not possible to do, unfortunately.
Simply said: all apps with dependencies to apps that used the “Library – Variable Storage” codeunit, simply failed, because the dependencies were not there yet in the previous apps, so it simply was not able to deploy them in the pipeline to a b17 container for: Checking breaking changes or installing the dependent apps.
There is always a solution .. Since I don’t want to just abandon DevOps, this is the only way I saw possible:
- Disable breaking changes in the yaml for this pullrequest. This is obviously not preferable, because despite the MANY changes I did, the pipeline is not going to make sure that I didn’t do any breaking changes.. . Fingers crossed.. .
- Approve all apps one by one, bottom up (apps with no dependencies first). This way, I make sure there is going to be a master-version of my app available for a next app (WITH the right dependencies), that is dependent of my bottom layered app. So, I had to push 65 pullrequests in the right order. Big downside was that I only see the real pipeline-issues when the pipeline was finally able to download the updated dependent extension. So no way for me to prepare (I couldn’t just let 65 apps build overnight and have an overview in the morning – I could only build the ones that already had all its dependent apps updated with the new dependency to the “Library – Variable Storage” app), and I had to solve things like breaking tests “on the go”. This all makes it very inefficient and time consuming.. . I reported it to Microsoft, and it seems that it makes sense for them to also see test-apps as part of the product, and to not do breaking changes in them anymore either (although I understand this is extra work for them as well… so, fingers crossed).
Some numbers
The preparation took us about 3 days of work: we changed 1992 files of a total of 3804 files, spread over 65 apps. So you could say we touched 50% of the product in 3 days (now you see why I really wanted to have our breaking changes-check as well ;-)?
The last step – the pullrequest – it took us an extra 2 days, which should have been just a matter of approving and fixing failing tests (only 5 tests out of 3305 failed after the conversion).
Any tips on how to solve the codecops?
Yes! But I’ll keep that for the next blogpost (this one is long enough already 😉 ).
6 comments
1 ping
Skip to comment form
Hi Eric,
As always a very interesting post! I’ve been through most of the pains you describe here and have mostly come to the same conclusions: One app per repo and branching is your friend on the way. We are using build tagging as an extra layer to help us with “breaking dependencies” and other breaking changes. This way we have multiple “active” versions, while preparing for an upgrade.
Besides your upgrade-prepare branches, do you also use release branching when you have no breaking changes, or do you normally release directly from master?
Author
Good tip, thanks!
We do have more than a hundred extensions and numbers keep growing. Once we update base app, we trigger pipelines for all those extensions. Since our base app is updated on 2 weeks cadence, we just trigger those pipelines manually by running a script. We are considering/planning to switch to monorepo for our base app, and it’s extensions. This way, we can do any code refactoring for all extensions in single commit. On the downside, you must build your own tooling to compile just changed extensions, and all its dependent extensions.
Author
I wouldn’t do it if I were you. You’ll solve one thing, and you’ll have problems to solve on others.
Consolidation is usually not a good thing.
Hi Eric, reading about ‘not a single PullRequest is able to be merged with the stable branch, if not all tests have run successfully’, I wonder what the added value of ALOpsCompile@2 is? If we want to include test as part of the branch validation policy, docker containers will still be needed to run the tests,
In which scenarios do you personally use ALOpsCompile@2 ?
Author
V2 gives faster feedback and relaxes the build server quite a lot: only when tests are really necessary, we’ll set up a docker container (we’ll be pushing breaking changes to the v2 compiler as well, soon, by the way). So if the pipeline fails on compile, on warnings, and soon on breaking changes, we’ll know within a few minutes and no unnecessary docker has been created or needs to be removed.
[…] Upgrade to Business Central V17 (part 1) – The Workflow […]